
(ML) 피처 스케일링
데이터는 서로 다른 범위, 피처를 가질 수 있습니다. 이를 동일한 수준으로 맞추는 작업을 피처 스케일링이라 부릅니다. 대표적인 방법으로 표준화, 정규화가 있습니다.
1. 표준화
표준화는 데이터의 피처 각각의 평균이 0, 분산이 1인 가우시안 정규 분포를 가진 값으로 변환하는 작업입니다. 아래의 공식을 사용해 변환합니다.
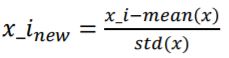
기존의 값에 피처의 평균 값을 빼준뒤, 피처의 분산으로 나누어주면 표준화된 값으로 변환됩니다.
서포트 벡터 머신, 선형 회귀, 로지스틱 회귀 등의 알고리즘은 데이터가 정규분포를 가진다고 가정하기 때문에 전처리 과정에서 표준화는 매우 중요합니다.
StandardScaler
StandardScaler 는 표준화를 위해 사용되는 클래스입니다. 변환 과정은 다음과 같습니다.
- 원 데이터의 평균, 분산값 확인
StandardScaler클래스를 이용하여 표준화된 데이터 생성
from sklearn.datasets import load_iris
import pandas as pd
iris = load_iris()
iris_data = iris.data
iris_df = pd.DataFrame(data=iris_data, columns=iris.feature_names)
print('<데이터의 평균 값>')
print(iris_df.mean())
print('\n<데이터의 분산 값>')
print(iris_df.var())
iris_df.head()
'''
<데이터의 평균 값>
sepal length (cm) 5.843333
sepal width (cm) 3.057333
petal length (cm) 3.758000
petal width (cm) 1.199333
dtype: float64
<데이터의 분산 값>
sepal length (cm) 0.685694
sepal width (cm) 0.189979
petal length (cm) 3.116278
petal width (cm) 0.581006
dtype: float64
'''
원 데이터의 평균, 분산을 확인한 결과, 단위는 cm로 동일하나 각 데이터 피처들의 평균과 분산이 다르고 정규분포를 따르지 않는것을 확인할 수 있습니다. StandardScaler 로 표준화 작업을 진행해 보겠습니다.
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
scaler.fit(iris_df)
iris_scaled = scaler.transform(iris_df)
iris_df_scaled = pd.DataFrame(data=iris_scaled, columns=iris.feature_names)
print('<데이터의 평균 값>')
print(iris_df_scaled.mean())
print('\n<데이터의 분산 값>')
print(iris_df_scaled.var())
'''
<데이터의 평균 값>
sepal length (cm) -1.690315e-15
sepal width (cm) -1.842970e-15
petal length (cm) -1.698641e-15
petal width (cm) -1.409243e-15
dtype: float64
<데이터의 분산 값>
sepal length (cm) 1.006711
sepal width (cm) 1.006711
petal length (cm) 1.006711
petal width (cm) 1.006711
dtype: float64
'''
피처의 데이터 값들의 평균이 0에 매우 가까운 값으로, 분산은 1에 매우 가까운 값으로 변환되었음을 확인할 수 있습니다.
Scaler 를 통해 변환된 데이터는 ndarray 형식으로 반환되으로 반드시 데이터프레임으로 변환해주어야 합니다!
2. 정규화
정규화는 서로 다른 피처의 크기를 통일하기 위해 크기를 변환해주는 작업입니다. 각 피처를 동일한 크기 단위로 비교하기 위해 최소 0, 최대 1의 값으로 변환해줍니다.
정규화 방법은 아래와 같이 나눌 수 있습니다.
MinMaxScaler- 피처 데이터의 최댓값의 절댓값으로 나눠주기
- 벡터 정규화
MinMaxScaler
정규화를 위한 MinMaxScaler 클래스를 사용합니다. 활용되는 공식은 아래와 같습니다.
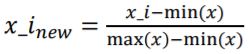
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(iris_df)
iris_scaled = scaler.transform(iris_df)
iris_df_scaled = pd.DataFrame(data=iris_scaled, columns=iris.feature_names)
print('<정규화된 데이터의 최댓값>')
print(iris_df_scaled.max())
print('\n<정규화된 데이터의 최솟값>')
print(iris_df_scaled.min())
'''
<정규화된 데이터의 최댓값>
sepal length (cm) 1.0
sepal width (cm) 1.0
petal length (cm) 1.0
petal width (cm) 1.0
dtype: float64
<정규화된 데이터의 최솟값>
sepal length (cm) 0.0
sepal width (cm) 0.0
petal length (cm) 0.0
petal width (cm) 0.0
dtype: float64
'''
피처들의 최댓값이 1, 최솟값이 0으로 변환된 것을 확인 할 수 있습니다.
최댓값의 절대값으로 나눠주기
간단히 각 피처 데이터의 최댓값의 절대값으로 나누어주는 방법입니다.
iris_df_abs_scaled = iris_df/abs(iris_df.max())
print('<abs 정규화된 데이터의 최댓값>')
print(iris_df_abs_scaled.max())
print('\n<abs 정규화된 데이터의 최솟값>')
print(iris_df_abs_scaled.min())
'''
<abs 정규화된 데이터의 최댓값>
sepal length (cm) 1.0
sepal width (cm) 1.0
petal length (cm) 1.0
petal width (cm) 1.0
dtype: float64
<abs 정규화된 데이터의 최솟값>
sepal length (cm) 0.544304
sepal width (cm) 0.454545
petal length (cm) 0.144928
petal width (cm) 0.040000
dtype: float64
'''
마찬가지로 값의 범위가 0~1 로 변환된 것을 확인 할 수 있습니다.
벡터 정규화
벡터 정규화는 어떤 벡터를 단위 벡터(크기가 1인 벡터)로 만드는 작업입니다. 벡터를 벡터 자기 자신의 크기로 나누어 주면 단위 벡터로 만들 수 있습니다.
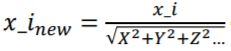
벡터의 크기(Norm)를 구하기 위해서는 numpy의 np.linalg.norm() 함수를 사용합니다.
iris_df_vector_scaled = iris_df/np.linalg.norm(iris_df)
print('<벡터 정규화된 데이터의 최댓값>')
print(iris_df_vector_scaled.max())
print('\n<벡터 정규화된 데이터의 최솟값>')
print(iris_df_vector_scaled.min())
print('\n<원 데이터프레임의 Norm>', np.linalg.norm(iris_df))
print('\n<벡터 정규화된 데이터프레임의 Norm> ', np.linalg.norm(iris_df_vector_scaled))
'''
<벡터 정규화된 데이터의 최댓값>
sepal length (cm) 0.080885
sepal width (cm) 0.045050
petal length (cm) 0.070647
petal width (cm) 0.025597
dtype: float64
<벡터 정규화된 데이터의 최솟값>
sepal length (cm) 0.044026
sepal width (cm) 0.020477
petal length (cm) 0.010239
petal width (cm) 0.001024
dtype: float64
<원 데이터프레임의 Norm> 97.66928892952994
<벡터 정규화된 데이터프레임의 Norm> 1.0
'''
값들이 0~1 사이의 범위를 가지게 되었으며 데이터프레임의 Norm이 1로 변환된 것을 확인할 수 있습니다.