
(ML) 데이터 인코딩
컴퓨터에서 인코딩이란, 사람이 인지할 수 있는 형태의 데이터를 약속된 규칙에 의해 컴퓨터가 이해할 수 있는 0과 1로 변환하는 과정입니다. 즉 데이터 인코딩은 머신러닝 알고리즘에서 사용가능하도록 데이터를 변환하는 것입니다.
사이킷런 머신러닝 알고리즘은 문자열 값을 입력 값으로 허용하지 않습니다. 그러므로 문자열 값들을 숫자 형으로 변환하는 인코딩 작업이 필요합니다.
머신러닝에서의 인코딩 방식을 대표적으로 레이블 인코딩, 원-핫 인코딩 두 가지가 있습니다. 각각의 인코딩 방식에 대해 공부해 보겠습니다.
1. 레이블 인코딩
레이블 인코딩은 데이터프레임의 열을 숫자값으로 변환하는 방법입니다.
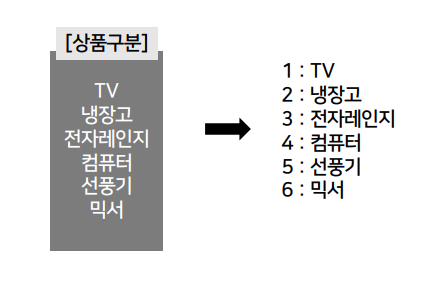
위 예시처럼 문자형으로 되어있는 열을 숫자형으로 변환합니다. 각각의 항목이 고유 번호를 부여받았음을 확인할 수 있습니다.
레이블 인코딩을 LabelEncoder 클래스로 구현해 봅시다.
from sklearn.preprocessing import LabelEncoder
items = ['TV', '냉장고', '전자레인지', '컴퓨터', '선풍기', '선풍기', '믹서', '믹서']
# LabelEncoder 를 객체로 생성한 후, fit()과 transform()으로 레이블 인코딩 수행
encoder = LabelEncoder()
encoder.fit(items)
labels = encoder.transform(items)
print('인코딩 변환값: ', labels)
'''
LabelEncoder()
인코딩 변환값: [0 1 4 5 3 3 2 2]
'''
구현에 사용된 fit transform 메서드를 잠시 살펴보겠습니다.
fit: 데이터 변환을 위한 기준 정보 설정, 매개변수를 이용해서 내부개체상태로 저장. (훈련시킨다 생각)transform:fit정보를 이용해서 데이터를 변환 (변환시킨다 생각)
데이터가 매우 많아질 경우, 어떤 문자열이 어떤 숫자로 변환되었는지 파악하기 어려워 집니다. classes_ , inverse_transform 을 이용해봅시다.
print('인코딩 클래스: ', encoder.classes_)
print('디코딩 원본값: ', encoder.inverse_transform([4,5,2,0,1,1,3,3]))
'''
인코딩 클래스: ['TV' '냉장고' '믹서' '선풍기' '전자레인지' '컴퓨터']
디코딩 원본값: ['전자레인지' '컴퓨터' '믹서' 'TV' '냉장고' '냉장고' '선풍기' '선풍기']
'''
classes_: 0번부터 순서대로 어떤 문자열이 변환된 것인지 보여줍니다.inverse_transform: 인코딩된 값을 받아 디코딩해줍니다.
레이블 인코딩은 머신러닝 알고리즘에서 숫자값의 크고 작음에 대한 특성이 작용할 수 있습니다. 가령 TV가 1의 값을 가지고 컴퓨터가 4의 값을 가진다면, 의도치 않게 머신러닝 알고리즘은 컴퓨터가 더 우수하다고 인식할 수 있는것이죠. 이는 알고리즘의 예측 성능을 저하시킵니다.
이러한 부분을 보완하기 위해 원-핫 인코딩이 사용됩니다.
2. 원-핫 인코딩
원-핫 인코딩은 새로운 열들을 추가해 그 값에 해당하는 칼럼에만 1을 표시하고 나머지 칼럼에는 0을 표시하는 방법입니다. 그림을 통해 자세히 알아보겠습니다.
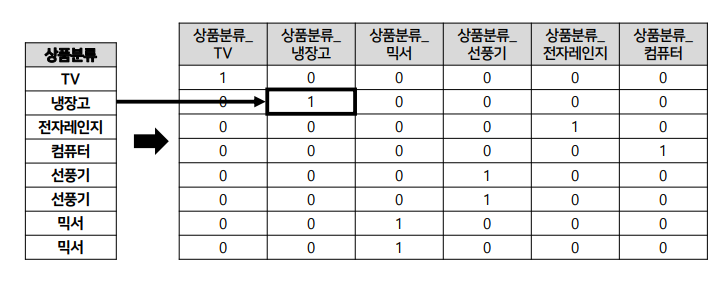
위 그림처럼 열들의 고유 값을 차원을 변환한 뒤, 해당하는 칼럼에만 1을 표시, 나머지에는 0을 표시합니다.
원-핫 인코딩을 수행하기 전에 아래 두 가지를 주의해야 합니다.
- 모든 문자열 값이 숫자형으로 변환되어야 합니다.
- 2차원 데이터를 입력값으로 가집니다.
원-핫 인코딩을 OneHotEncoder 클래스로 구현해 보겠습니다.
from sklearn.preprocessing import OneHotEncoder
import numpy as np
items = ['TV', '냉장고', '전자레인지', '컴퓨터', '선풍기', '선풍기', '믹서', '믹서']
encoder = LabelEncoder()
encoder.fit(items)
labels = encoder.transform(items)
labels = labels.reshape(-1, 1)
labels
oh_encoder = OneHotEncoder()
oh_encoder.fit(labels)
oh_labels = oh_encoder.transform(labels)
print('원-핫 인코딩 데이터')
print(oh_labels.toarray())
print('원-핫 인코딩 데이터 차원')
print(oh_labels.shape)
'''
LabelEncoder()
array([[0],
[1],
[4],
[5],
[3],
[3],
[2],
[2]], dtype=int64)
OneHotEncoder()
원-핫 인코딩 데이터
[[1. 0. 0. 0. 0. 0.]
[0. 1. 0. 0. 0. 0.]
[0. 0. 0. 0. 1. 0.]
[0. 0. 0. 0. 0. 1.]
[0. 0. 0. 1. 0. 0.]
[0. 0. 0. 1. 0. 0.]
[0. 0. 1. 0. 0. 0.]
[0. 0. 1. 0. 0. 0.]]
원-핫 인코딩 데이터 차원
(8, 6)
'''
판다스의 get_dummies 메서드를 사용하면 숫자형 값 변환없이 원-핫 인코딩을 쉽게 구현 할 수 있습니다.
import pandas as pd
df = pd.DataFrame({'item': ['TV', '냉장고', '전자레인지', '컴퓨터', '선풍기', '선풍기', '믹서', '믹서']})
oh = pd.get_dummies(df)
print(oh)
'''
item_TV item_냉장고 item_믹서 item_선풍기 item_전자레인지 item_컴퓨터
0 1 0 0 0 0 0
1 0 1 0 0 0 0
2 0 0 0 0 1 0
3 0 0 0 0 0 1
4 0 0 0 1 0 0
5 0 0 0 1 0 0
6 0 0 1 0 0 0
7 0 0 1 0 0 0
'''