
(ML) 분류의 성능 평가
[ML] 분류의 성능 평가
머신러닝의 분류 기법의 성능을 평가하는 다양한 지표를 공부해보자
정확도(Accuracy score)
정확도는 실제 데이터와 예측 데이터가 얼마나 같은지를 나타내는 지표이다.

-
Code (sklearn)
from sklearn.linear_model import LogisticRegression from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score lr_clf = LogisticRegression() X = cancer.data y = cancer.target X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=23) lr_clf.fit(X_train, y_train) pred = lr_clf.predict(X_test) acc_score = accuracy_score(y_test, pred) print('정확도: ', round(acc_score, 4)) # --- Output --- # 정확도: 0.9474
오차 행렬(Confusion matrix)
오차 행렬은 분류 모델의 예측 오류가 얼마나, 어떤 유형으로 나타나는지를 나타내는 지표이다.
4분면 행렬로 나타내며, 예측 값, 실제 값에 따라 TN, FP, FN, TP 값을 표시한다.
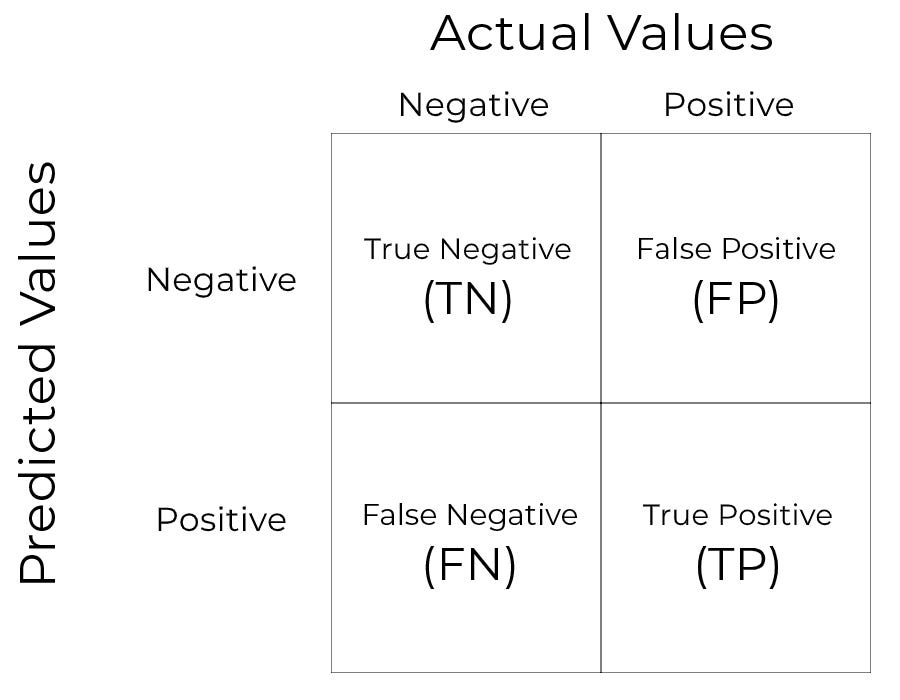
세부 지표를 살펴보자
- TN (True Negative) : Negative로 예측했으며, 실제 값도 Negative인 경우
- FP (False Positive) : Positive로 예측했으나, 실제 값은 Negative인 경우
- TP (True Positive) : Positive로 예측했으며, 실제 값도 Positive인 경우
-
FN (False Negative) : Negative로 예측했으나, 실제 값은 Positive인 경우
-
Code (sklearn)
from sklearn.metrics import confusion_matrix conf_matrix = confusion_matrix(y_test, pred) conf_matrix # --- Output --- ''' array([[ 58, 5], [ 4, 104]]) '''
정밀도(Precision)
정밀도는 Positive로 예측한 데이터 중, 예측 값과 실제 값이 모두 Positive인 데이터의 비율을 나타내는 지표이다.

-
Code (sklearn)
from sklearn.metrics import precision_score precision = precision_score(y_test, pred) print('정밀도: ', round(precision, 4)) # --- Output --- # 정밀도: 0.9541
재현율(Recall)
재현율은 실제 값이 Positive인 데이터 중, 예측 값과 실제 값이 모두 Positive인 데이터의 비율을 나타내는 지표이다.

-
Code (sklearn)
from sklearn.metrics import recall_score recall = recall_score(y_test, pred) print('정밀도: ', round(recall, 4)) # --- Output --- # 재현율: 0.963
F1 score
F1 스코어는 정밀도와 재현율을 결합한 지표로써, 두 지표가 어느 한쪽으로 치우쳐져있는지를 나타내는 지표이다. 정밀도와 재현율이 한쪽으로 치우치지 않을 경우 높은 값을 가진다.

-
Code (sklearn)
from sklearn.metrics import f1_score f1 = f1_score(y_test, pred) print('F1: ', round(f1, 4)) # --- Output --- # F1: 0.9585